Software Design X-Rays: Fix Technical Debt with Behavioral Code Analysis by Adam Tornhill

This book made me angry. Multiple times. If it wasn’t so short, I would’ve not finished it. But between the many illustrations and many, many, many, many, many repetitions as well as long-drawn-out self-references (I’ll come back to this shortly) it is possible to finish in one sitting.
So, the premise seemed great. Look at the code, but consider the human dimension. Consider the human dimension, but do it in a reasonable way, with metrics and whatnot. Find the hot spots of your technical debt that will actually be valuable to fix. Yay.
But there is not much meat on the bones of that premise. What’s there instead? Well, for one, the reader is fed with “links” like this one, calling out a section’s name in full and giving the page number:
The X-Ray analysis you learned in ‘Use X-Rays to Get Deep Insights into Code’, on page 27 […]
or this one, repeated many times:
We return to this topic in the exercises and we’ll explore it in much more depth in the second part of this book. I promise.
or this one — note that this is continuous text, not sentences yanked from different places:
Let’s look at the code, shown in the figure on page 53, to see how we can refactor it. As you see in the figure on page 53, […]
There are some bites inflicted on the usual suspects:
[…] would otherwise become outdated faster than this week’s JavaScript framework.
[…] has wrecked more software projects than even Visual Basic 6.
I suppose this is meant as little jokes, but in my humble opinion this is a low blow which looks out of place.
Sometimes there’s a nice bit of practical advice like this one:
Human memory is fragile and cognitive biases are real, so a project decision log will be a tremendous help in keeping track of your rationale for accepting technical debt. Jotting down decisions on a wiki or shared document helps you maintain knowledge over time.
But. Oh, so many but:s:
-
This will only work if it’s always up to date. And it’s basically documentation. When was the last time anyone worked at a company where the docs were up to date? What will make the decision log any easier to maintain?
-
Wiki:s get replaced by the new shiny thing and shared documents don’t get shared with new hires because oops; it’s risky to separate the decisions made (i.e. the code) from their rationale (i.e. the decision log). How would this be addressed?
-
Such a log, wherever it may be, could be useful to get a high-level overview (as opposed to nitty-gritty of all the commit messages or docs one might read). But for that, every line of such a log has to be concise. Short but insightful for the reader. And everyone on the team has to keep it up. Now, what does that remind me of… Oh right, commit messages' subject lines! How good is an average team in that? This good.
…to summarize, while a well-made decision log would be like an amazing cheat sheet on the project’s life, writing well is very hard, and figuring out how to make a decision log tick for your team without investing too much effort is a little project in itself. In one of the teams I was part of, we had a similar log explaining the changes in our work process. The idea was to write down the change and the rationale if not everyone in the team is present when the decision is made, so that the others can catch up after vacation, for example. Just one line: the date, the change, and the reason. We were tweaking the process all the time so it did help. But many of the log lines were imprecise, incomplete, inconsistent, and so on. To really catch up, it was often necessary to supplement with talking to your team. And writing that log was (1) about things fresh in memory, (2) without the need to aggregate for a high-level overview, (3) without complex technical details. The devil in these details is so fat he put out the hell fire by taking up all space and robbing it of air.
So, mixed feelings.
Another example of a practical advice which immediately raised
“but:s”[1] was to give a name like Dumpster.java to a
file full of low cohesion code.[2] The author claims that such a name makes it clear
that the module needs work and discourages its further growth. “After all, who
wants to put their carefully crafted code in a dumpster?”, he asks. My question
would be: who wants to see the code they carefully wrote a year ago being renamed into
Dumpster.java? Yay teamwork…
But mostly my anger at this book comes from the high expectations. It brings up something very interesting but then there is just… not much. For example, it postulates that the structure of the development organization is a stronger predictor of defects than any code metrics. Isn’t this intriguing as heck? And it actually references a paper! Alas, when you check the paper, it turns out a couple of people with @microsoft.com emails and one more from the University of Maryland looked at Windows Vista and… that’s it. They begin the section on the existing works overview with quoting “The Mythical Man Month” on the topic of the Babel Tower project. I kid you not, the Old Testament’s Tower of Babel is used as the first source for the organizational setup discussion. No offense to Fred Brooks, the author of “The Mythical…” here, it’s a great analogy. But quoting it in a paper as an “observation” is going too far for my taste — one can not observe mythical towers. Nitpicking aside, there’s the issue of applicability. While the paper boasts being “one of the largest studies of commercial software” and the authors have clearly done a lot of work, it is at the end of the day just one case study, a case study of Microsoft. They point out as much themselves in the “Threats to validity” section. A case study can be great and deep and whatever, but one case study of one company is hardly enough to make sweeping statements. Even if they are intriguing. Especially if they are intriguing. Here’s the key table of the paper, by the way:
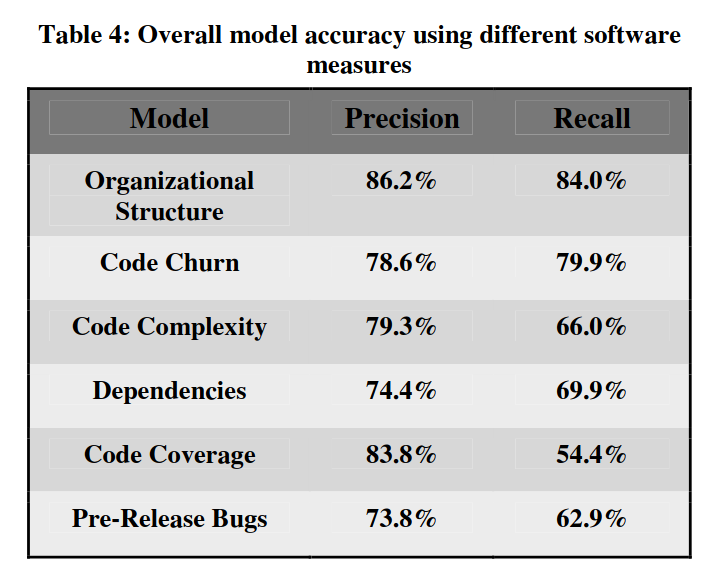
(roughly speaking, precision = when the model found something, is it actually the right thing to find; recall = when there is something to find, does the model find it)
The same high expectations brought me trouble when it came to the core of the book, that is the analysis of code bases. A lot of space is dedicated to uncovering the “hot spots” in a code base, those files/modules/functions which everything depends on but nobody really understands, so the team members are afraid to touch it, but have to touch it, and it breaks, and blah blah. Well, cool, but (a) figuring this out is a one-liner in shell, and (b) everyone on the team knows those spots. If you’ve worked there for two weeks, you’ll know which giant file nobody wants to touch but touches anyway, and if you haven’t worked there for two weeks, you can just ask anyone who has.
The reading pleasure also does not increase from the small mishaps like “In the this figure” (p.54) and “There a several good books” (p. 58) In addition, lots of footnotes in the book just occupy space with their endless pointing to Wikipedia for no good reason.
Still, the book uses recent and relevant examples and touches a whole score of
intriguing topics. What will happen when all the microservices of today become
the new technical debt? Should you use the data mined from git log to assess
performance of the developers? What to do about the knowledge loss when
developers leave? How do the 30k-LOC monsters with through-the-roof complexity
appear? Should you package by component or by feature? What about creating a
bug-fixing/maintenance team? Some answers are insightful, some naive. Most of
them refer you to using the tool sold by the author’s company. I wonder
why.[3] The only advantage that
the tool has over some thoughtful poking through git log and git blame is
visualization. Which could be helpful if you’re a consultant who jumps from one
gig to another and for some reason can not talk to the developers on site. Who
knows.
So maybe this is a good book to throw into a room full of programmers to cause a debate. Nice for book clubs, I guess?
★★☆☆☆
(252 pages, ISBN:9781680502725, Worldcat, Open Library)
There is no comments section, but if you'd like to give feedback or ask questions about this post, please contact me.